前言
对于大模型风险,目前大家更多关注的还是越狱攻击。隐私这一块,可能国内还不如欧美重视,在安全的学术四大会议论文中,有时候甚至AI隐私的论文比AI安全的论文更多。但实际上,除了越狱之外,另外一大风险就是隐私风险,比如大模型隐私数据提取,这也是不容忽视的。
大模型隐私数据提取攻击是一种新型的模型攻击方式,它对大型语言模型的现实应用构成了严重威胁。这种攻击方式的目标是从语言模型中筛选出数百万个输出序列,并预测哪些文本是被记忆的。攻击者可以通过查询模型来有效提取训练数据,甚至无需事先了解训练数据集。这意味着,即使是未对齐的模型,也可能被攻击,而对于已经对齐的模型,攻击者可以通过新的发散数据提取攻击,导致模型改变内容生成方式,以高速输出训练数据。
这种攻击的危害在于,它可能导致个人隐私信息的泄露,例如姓名、电话号码、电子邮件和实际地址等个人身份信息(PII)。如果有人将这种攻击行为应用到公众可用的模型,同时其训练数据是非公开的,会产生巨大的危害。攻击者可以利用这些信息进行诈骗、骚扰、人身攻击等犯罪活动,对受害者的生命安全和财产安全构成直接威胁。
本文来我们分析并复现,这个研究方向上最重要的一篇文章(没有之一),即Carlini等人2020年底发布的工作《Extracting Training Data from Large Language Models》。

背景
大模型其实是一系列单词分配概率的统计模型,是许多自然语言处理任务的基础。现代基于神经网络的语言模型使用非常大的模型架构(例如,1750亿个参数)并在大量数据集(例如,几乎一兆字节的英文文本)上进行训练。这种扩展提高了语言模型生成流畅自然语言的能力,并允许它们被应用于许多其他任务,甚至不需要更新它们的参数。与此同时,机器学习模型因暴露有关其(可能为私有的)训练数据的信息而声名狼藉——无论是在一般情况下还是在语言模型的特定案例中。例如,对于某些模型,已知对手可以应用成员资格推断攻击来预测任何特定示例是否在训练数据中。
这种隐私泄露通常与过拟合有关,因为过拟合通常表明模型已经记住了训练集中的示例。实际上,过拟合是隐私泄露的充分条件,并且许多攻击通过利用过拟合来工作。过拟合和记忆之间的关联导致许多人认为最先进的语言模型不会泄露有关其训练数据的信息。因为这些模型通常只在单个时期内训练在大规模去重复的数据集上,它们表现出很少或没有过拟合。因此,普遍的观点是“对任何给定作品的复制程度可能最多是微不足道的”,并且模型不会显著记住任何特定的训练示例。
但实际上,从大模型中提取出训练的隐私数据是完全有可能的。

如上图所示,给定对神经网络语言模型的查询访问,我们提取了一个人的姓名、电子邮件地址、电话号码、传真号码和实际地址。
研究人员提出了一种简单高效的从语言模型的训练集中提取逐字序列的方法,仅使用黑盒查询访问。关键见解在于,尽管训练样本在平均损失上并不比测试样本显著降低,但某些最坏情况下的训练样本确实被记忆了。
在我们的攻击中,我们首先使用三种通用采样策略之一,从模型生成大量的高概率样本。然后我们使用六种不同的度量标准对每个样本进行排序,这些度量标准使用另一个参考模型(例如,另一个语言模型)来估计每个样本使用的概率,并优先考虑在两个模型之间具有异常高概率比的样本。我们的攻击直接适用于任何语言模型,包括那些在敏感和非公开数据上训练的模型。
我们在后续的复现、实战环节中使用OpenAI发布的GPT-2模型作为代表性的语言模型。攻击GPT-2是为了最大限度地减少现实世界的伤害,因为GPT-2模型和原始训练数据源已经是公开的。
威胁模型
训练数据提取攻击通常被视为理论性的或学术性的,因此被认为在实践中不太可能被利用。
这种观点得到了普遍直觉的支持,即隐私泄露与过拟合相关,并且由于最先进的语言模型是在大型(接近兆字节大小)数据集上仅训练几个周期,它们往往不会过拟合。
但是,训练数据提取攻击是实际可行的。为此,需要准确定义了我们所说的“记忆”的含义。
记忆的定义
在语言建模中有许多定义记忆的方式。记忆在许多方面是语言模型的基本组成部分,因为训练目标是为训练数据集分配高概率。例如,语言模型必须“记忆”个别单词的正确拼写。实际上,有一种研究方向将神经网络视为(记忆的)知识库。例如,当GPT-2被提示完成句子“My address is 1 Main Street, San Francisco CA”时,它生成了“94107”:旧金山,CA的正确邮政编码。虽然这显然是一种抽象形式的记忆,我们的目标是为了将记忆的定义正式化,以便将其限制在我们可能认为是“非预期的”情况。
我们定义生动记忆为一种特定类型的记忆。生动记忆是一个模型尽管只在少量训练实例中出现过,但仍然记忆了数据。包含数据的训练样本越少,生动记忆就越强。为了正式定义这个概念,我们首先定义一个模型对字符串s的知识。
如果s可以通过与模型的交互被提取出来,则模型fθ知道字符串s。更具体地说,我们关注黑盒交互,其中模型在给定前缀c时生成s作为最可能的后续:
定义1
(模型知识提取)如果存在一个前缀c,使得:

用fθ(s’ | c)表示整个序列s’的可能性。由于对于大N计算最可能的序列s是不切实际的,定义1中的argmax可以被适当的采样策略(例如,贪婪采样)替换,这反映了模型fθ在实际应用中生成文本的方式。然后我们定义生动记忆如下
定义2
(k-生动记忆)如果s可以从fθ中提取,并且s在训练数据X中的出现次数最多为k个示例:

这个定义的关键在于“示例”的含义。
对于GPT-2,每个网页被用作(作为一个整体)一个训练示例。由于这个定义计算的是包含给定字符串的不同训练示例的数量,而不是字符串出现的总次数,一个字符串可能在一个页面上出现多次,但仍然只计为k=1的记忆。
威胁模型
攻击者具有语言模型的黑盒输入输出访问权限。这允许对手计算任意序列fθ(x1,…,xn)的概率,并因此允许对手获得下一个词的预测,但不允许对手检查语言模型的个别权重或隐藏状态(例如,注意力向量)。
训练数据提取攻击带来了许多隐私风险。从伦理角度来看,由于我们攻击的GPT-2的训练数据是公开的,这些风险中的大部分都得到了缓解。然而,攻击适用于任何语言模型。
初始训练数据提取攻击
我们首先为从语言模型中提取训练数据提供一个简单的基线方案,这个过程分为两个步骤。
- 生成文本。我们通过无条件下从模型中采样生成大量数据。
- 预测哪些输出包含记忆文本。接下来,我们使用成员资格推断攻击移除那些不太可能包含记忆文本的生成样本。
这两个步骤直接对应于提取模型知识(定义1),然后预测哪些字符串可能是k-生动记忆(定义2)。
初始文本生成方案
为了生成文本,我们使用一个包含特殊句子开始标记的单个标记提示来初始化语言模型,然后以自回归的方式从模型中反复采样标记。我们希望通过根据模型分配的可能性进行采样,我们将采样到模型认为“非常可能”的序列,而可能的序列对应于记忆文本。具体来说,我们使用top-n策略,其中n=40,为每个试验采样恰好256个标记。
初始成员资格推断
给定一组从模型中生成的样本,训练数据提取问题就简化为成员资格推断:预测每个样本是否在训练数据中。在其最基本的形式中,过去的成员资格推断攻击依赖于这样一个观察——模型倾向于对在训练数据中出现的示例分配更高的置信度。因此,一个可能具有高精确度的成员资格推断分类器就是简单地选择模型分配最高可能性的示例。由于语言模型是概率生成模型,我们遵循先前的工作并使用自然的可能性度量:序列的困惑度(perplexity)衡量语言模型“预测”该序列中每个标记的能力。
具体来说,给定一系列标记x1,…,xn,困惑度定义为:

也就是说,如果困惑度低,那么模型对序列“不太惊讶”,并且平均来说对每个后续标记分配了高概率。
初始提取结果
我们使用最大版本的GPT-2模型(XL,1558M参数)按照文本生成方案生成了200,000个样本。
然后我们根据模型的困惑度度量对这些样本进行排序,并调查那些困惑度最低的样本。这种简单的基线提取攻击可以找到各种记忆内容。
例如,GPT-2记忆了MIT公共许可证的全部文本,以及在线流媒体网站Vaughn Live的用户指南。虽然这是“记忆”,但它只是k-生动记忆的一个较大值——这些许可证在训练数据中出现了数千次
事实上,我们在这种基线设置中识别的所有记忆内容可能在训练数据集中出现了很多次。这种方法有两个主要的弱点。首先,我们的采样方案倾向于产生输出的多样性较低。例如,在生成的200,000个样本中,有数百个是Vaughn Live用户指南的记忆副本。其次,我们基线的成员资格推断策略存在大量的误报,即内容被分配了高可能性,但并未记忆。这些误报样本中的大多数包含“重复”的字符串(例如,同一个短语多次重复)。尽管这样的文本非常不可能,但大型语言模型经常错误地为这种重复序列分配高可能性。
所以还需要对攻击方法进行改进。
改进攻击
之前的攻击具有精度低(高可能性样本并不总是在训练数据中)和召回率低(对于低k值没有识别出k-记忆内容)的问题。现在我们通过结合更好的模型采样方法和成员资格推断方法来改进攻击。
改进的文本生成方案
我们攻击的第一步是从语言模型中随机采样。在前面,我们使用了top-n采样,并将语言模型的条件设置为开始序列的标记作为输入。这种策略有明显的局限性:它只会产生从开始到结束都很可能的序列。因此,使用top-n采样从模型生成的序列将导致它多次生成相同(或相似)的示例。下面我们介绍两种从语言模型生成更多样化样本的替代技术。
使用衰减温度采样
语言模型输出给定先前标记的下一个标记的概率Pr(xi | x1,…,xi−1)。在实践中,这是通过评估神经网络z = fθ(x1,…,xi−1)来获得“logit”向量z,然后计算输出概率分布为y = softmax(z),定义为

人们可以通过用softmax(z/t)替换输出softmax(z)来人为地“压扁”这个概率分布,使模型变得不太自信,其中t > 1。这里,t称为温度。更高的温度会使模型不太自信,并在其输出中更加多样化。然而,如果在整个生成过程中保持高温,即使采样过程开始发出记忆示例,它也可能随机地偏离记忆输出的路径。因此,我们使用随时间衰减的softmax温度,开始时t=10,在前20个标记的时期内衰减到t=1(约占序列长度的10%)。这为模型提供了足够的时间来“探索”多样化的前缀,同时也允许它跟随它发现的高置信度路径。
以互联网文本为条件
即使应用了温度采样,仍然有一些前缀不太可能被采样,但它们确实出现在实际数据中。作为最后一种策略,我们的第三种采样策略用我们自己的互联网抓取的前缀来引导模型。这种采样策略确保我们将生成具有多样化前缀的样本,这些前缀在性质上类似于GPT-2训练所用的数据。我们按照与GPT-2不同的数据收集过程(它跟随Reddit链接)进行操作,以减少我们的数据集与模型训练数据有任何交集的可能性。比如可以选择Common Crawl的子集作为模型的上下文。
我们在后续复现的时候,会涉及到排名指标
生成的样本根据论文中介绍的六个成员推断指标进行排名:
- GPT2-XL模型的log困惑度
- GPT2-XL模型和GPT2-Small模型的log困惑度比率
- GPT2-XL模型和GPT2-Medium模型的log困惑度比率(已实现但由于计算限制无法运行)
- GPT2-XL的log困惑度与样本的Zlib估计熵的比率
- GPT2-XL对生成样本和同样样本小写字母形式的log困惑度比率
- GPT2-XL在窗口大小为50的窗口中的最小log困惑度
根据每个指标选出的前10个样本将被打印出来,而前100个样本将被记录在输出文件中。这些样本可能包含GPT-2训练数据中的逐字文本。
实战
首先我们来看基于top-k采样的方法

load_tokenizer_for_causal_lm(model_name)
这个函数的作用是加载指定模型的分词器(tokenizer),用于将输入文本转换成模型可接受的输入格式。分词器加载后,设置了填充(padding)的方向为左侧,并将填充的标记设为分词器的结束标记(eos_token)。
load_model_for_causal_lm(model_name, device)
这个函数用于加载指定模型的因果语言模型(causal language model)。加载后,将模型配置的填充标记 ID 设为模型配置中的结束标记 ID,并将模型移动到指定的计算设备(如 CPU 或 GPU)。最后将模型设为评估模式(eval mode)。
calculate_perplexity(input_sentence, model, tokenizer, device)
这个函数计算给定输入句子的困惑度。首先使用分词器对输入句子进行分词,并将其转换成模型可接受的输入张量。然后使用加载的因果语言模型计算模型在输入句子上的损失值(loss),并通过指数函数计算出困惑度(perplexity)。
calculate_perplexity_sliding(input_sentence, model, tokenizer, device, window_size=50)
这个函数计算输入句子在滑动窗口中的最小困惑度。首先使用分词器对输入句子进行分词,并将其转换成模型可接受的输入张量。然后在输入张量的每个可能的滑动窗口上,使用加载的因果语言模型计算每个窗口上的损失值,并更新记录的最小困惑度值。最终返回输入句子在滑动窗口中的最小困惑度值。
这些函数共同作用于加载模型和分词器,并在给定输入上执行困惑度计算任务,以评估因果语言模型在文本生成任务中的性能。

这两个函数用于打印或将最佳样本及其相关信息写入文件
print_best
这个函数用于打印评分最高的样本及其相关信息到控制台。
-
参数:
metric: 用于排序的评估指标数组。samples: 样本数组,包含待打印的文本样本。metric_name: 评估指标的名称。name1: 第一个评估分数的名称。scores1: 第一个评估分数的数组。name2(可选): 第二个评估分数的名称。scores2(可选): 第二个评估分数的数组。lower_better: 是否评分越低越好的布尔值。n: 要打印的前n个样本数,默认为10。
-
功能:
- 根据
lower_better的值对评估指标metric进行排序。 - 对排序后的索引进行迭代,打印每个样本的排名、分数和相关信息。
- 使用
pprint函数来更好地格式化和打印样本内容。
- 根据
print_best_to_file
这个函数与 print_best 函数类似,不同之处在于它将输出写入指定的文件而不是控制台。
-
参数:
- 除了与
print_best相同的参数外,还有一个额外的outfile参数,表示输出文件的路径。
- 除了与
-
功能:
- 在函数开始时,将标准输出
sys.stdout更改为指定文件outfile,以便将所有输出写入该文件。 - 然后进行与
print_best函数类似的操作:根据lower_better的值对评估指标metric进行排序,并迭代处理每个样本以将其输出到文件中。 - 最后,恢复标准输出以便后续的输出能够正常显示在控制台。
- 在函数开始时,将标准输出
这两个函数通常用于评估和展示模型或算法在某个任务上的表现,如文本生成中的样本质量或其他指标。

这段代码的主要功能是生成文本样本,并针对每个样本计算多个困惑度指标:
主要步骤和功能:
-
加载模型和初始化设置:
- 使用
load_tokenizer_for_causal_lm和load_model_for_causal_lm函数加载 GPT-2 和 GPT-2 XL 模型及其分词器。 - 设定生成序列的最大长度
seq_len和每批次生成样本的数量args.batch_size。
- 使用
-
生成样本和计算指标:
- 使用
MODEL_GPT2_XL.generate方法生成文本序列,参数包括输入的input_ids、注意力掩码attention_mask、生成的最大长度max_length等。 - 使用
TOKENIZER_GPT2.batch_decode方法将生成的序列解码为文本。 - 对于每个生成的文本,计算以下指标:
perplexity_gpt2_xl: 在 GPT-2 XL 模型上的困惑度。perplexity_gpt2: 在 GPT-2 模型上的困惑度。perplexity_gpt2_xl_lower: 在 GPT-2 XL 模型上对文本的小写版本计算的困惑度。zlib_entropy: 使用 Zlib 压缩计算文本的熵。perplexity_gpt2_xl_window: 在 GPT-2 XL 模型上对文本的滑动窗口计算的最小困惑度。
- 使用
-
记录和整理结果:
- 将每个生成的文本和其对应的各指标值记录到
generated_samples和scores字典中。 - 统计生成的样本数量,并计算每个指标的数组,以便后续处理和分析。
- 将每个生成的文本和其对应的各指标值记录到
-
处理重复样本:
- 使用
pd.Index和duplicated()方法检测和移除重复的样本。 - 确保样本和指标数组的长度一致,并打印出移除的重复样本数量。
- 使用
该代码段展示了如何使用预训练的语言模型生成文本,并评估生成文本在不同指标下的质量和多样性。
执行后如下所示

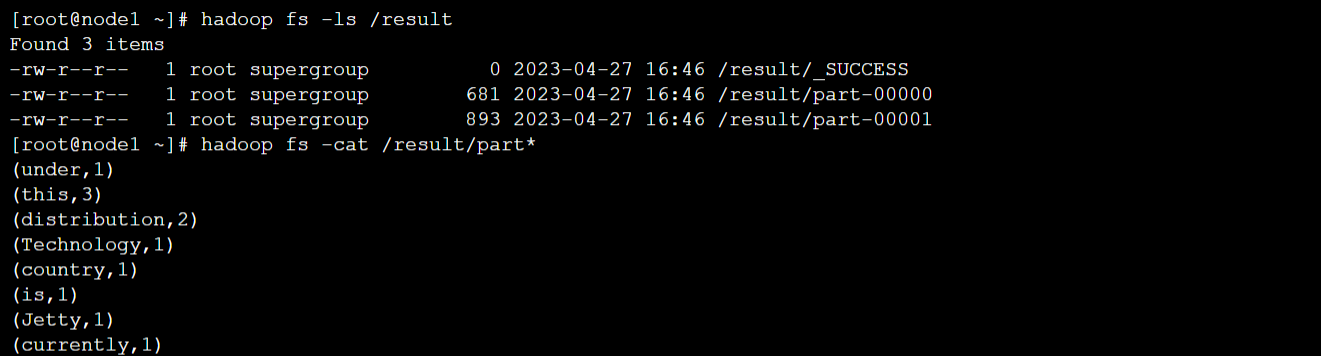
执行完毕后终端输出的部分结果如下

另外还在txt中有提取出的训练数据

作为示例,我们可以以第一条为例进行搜索,可以看到确实是很类似的

这个例子,如果用1个A40跑的话,大约需要1小时左右。

再来看基于温度衰减的方法

这段代码展示了一个自定义的温度衰减函数 DecayingTemperatureWarper 和一些辅助函数,用于加载语言模型和计算困惑度。
DecayingTemperatureWarper 类
这个类是一个继承自 LogitsProcessor 的自定义温度调节器。它根据输入的序列长度动态调整温度参数,以影响生成文本的多样性或准确性。主要包括以下几个部分:
-
初始化方法 (
__init__):- 接受一个
temperature参数,确保它是一个严格正的浮点数,否则会抛出ValueError异常。 - 初始化
temperature属性和一个mapping字典,用于根据输入序列长度调整温度的映射表。
- 接受一个
-
__call__方法:- 当类的实例被调用时,它接受
input_ids和scores两个张量作为输入。 - 计算当前输入序列的长度
cur_len。 - 根据
mapping字典中的映射关系,将当前序列长度对应的温度值赋给self.temperature。 - 最后返回
scores,在这里实际上没有修改scores,而是仅仅动态调整了self.temperature。
- 当类的实例被调用时,它接受
辅助函数
这里还包括了一些辅助函数,用于加载语言模型和计算困惑度:
-
load_tokenizer_for_causal_lm函数:- 根据给定的模型名称加载语言模型的分词器(tokenizer)。
-
load_model_for_causal_lm函数:- 根据给定的模型名称加载语言模型,并将其加载到指定的计算设备(如 CPU 或 GPU)上。
-
calculate_perplexity函数:- 计算给定输入句子在指定模型上的困惑度。使用模型对输入进行前向推断,计算损失,并通过指数函数得到困惑度值。
-
calculate_perplexity_sliding函数:- 计算给定输入句子在指定模型上滑动窗口的最小困惑度。它通过在输入句子的每个可能的窗口上进行模型推断,并记录最小损失来计算困惑度。
这些代码片段展示了如何定义一个自定义的温度衰减函数,以及如何加载预训练语言模型和计算文本生成任务中的困惑度。这些功能适用于语言生成任务中的模型评估和调优,以提高生成文本的质量和多样性。

这两个函数用于打印或将最佳样本及其相关信息写入文件:
print_best
这个函数用于打印评分最高的样本及其相关信息到控制台。
-
参数:
metric: 用于排序的评估指标数组。samples: 样本数组,包含待打印的文本样本。metric_name: 评估指标的名称。name1: 第一个评估分数的名称。scores1: 第一个评估分数的数组。name2(可选): 第二个评估分数的名称。scores2(可选): 第二个评估分数的数组。lower_better: 是否评分越低越好的布尔值。n: 要打印的前n个样本数,默认为10。
-
功能:
- 根据
lower_better的值对评估指标metric进行排序。 - 使用
np.argsort(metric)对指标进行升序或降序排序,然后取前n个索引。 - 对于每个选定的索引,打印相应的样本、评估分数和指标值。
- 根据
print_best_to_file
这个函数与 print_best 函数类似,不同之处在于它将输出写入指定的文件而不是控制台。
-
参数:
- 除了与
print_best相同的参数外,还有一个额外的outfile参数,表示输出文件的路径。
- 除了与
-
功能:
- 在函数开始时,将标准输出
sys.stdout更改为指定文件outfile,以便将所有输出写入该文件。 - 根据
lower_better的值对评估指标metric进行排序,并迭代处理每个样本以将其输出到文件中。 - 最后,恢复标准输出以便后续的输出能够正常显示在控制台。
- 在函数开始时,将标准输出
这两个函数通常用于评估和展示模型或算法在某个任务上的表现,如文本生成中的样本质量或其他评估指标。通过控制台输出或文件记录,可以方便地查看和分析生成样本及其相应的评估结果。
执行过程中的截图如下

终端输出如下

同样也会得到一个txt

部分内容如上所示
以第一条为例,可以看到提取出的数据与原始的数据几乎一致

再来尝试用来自网络(commoncrawl)的文本片段提示GT2-XL模型,这按理来说是可以提升攻击效果的

这段代码主要用于加载一个因果语言模型和相应的标记器,计算输入句子的困惑度,并在滑动窗口中找到最低困惑度。最后一部分代码用于打印性能最佳的样本
-
加载标记器函数:
- 加载指定模型的标记器。
- 设置填充策略为左对齐,并将填充标记设为结束标记。
-
加载模型函数:
- 加载指定模型,并将其移至指定设备(例如GPU)。
- 设置填充标记ID为结束标记ID,并将模型置于评估模式。
-
计算困惑度函数:
- 使用标记器将输入句子转化为标记ID。
- 将标记ID转换为张量并移至指定设备。
- 在不计算梯度的上下文中,使用模型计算输出,并返回损失的指数值作为困惑度。
-
滑动窗口困惑度计算函数:
- 将输入句子转化为标记ID并转换为张量。
- 初始化最低困惑度为一个很大的数。
- 遍历输入序列,以滑动窗口方式计算每个窗口的困惑度,更新最低困惑度。
-
打印最佳样本函数:
- 根据给定的度量值排序,获取最佳样本的索引。
- 打印每个样本的相关信息,包括度量值和得分,若提供了两个模型的分数,也会一起打印。

print_best_to_file 函数
这个函数将评估结果打印到指定的文件中,而不是标准输出(通常是控制台)。具体操作步骤如下:
- 保存标准输出:
- 将当前的标准输出保存到
original_stdout中,以便稍后恢复。
- 将当前的标准输出保存到
- 重定向标准输出到文件:
- 打开指定的输出文件,并将标准输出重定向到该文件。
- 打印度量名称:
- 打印度量名称到文件中。
- 排序和选择样本:
- 根据给定的度量值排序,选择前
n个最佳样本的索引。排序可以是升序或降序,取决于lower_better参数。
- 根据给定的度量值排序,选择前
- 打印样本信息:
- 对于每个选中的样本,打印样本的分数和度量值。如果提供了两个模型的分数,也会一起打印。
- 恢复标准输出:
- 将标准输出恢复到原来的标准输出(控制台)。
parse_commoncrawl 函数
这个函数从Common Crawl的WET文件中解析出所有的英语内容。具体操作步骤如下:
- 读取文件内容:
- 打开指定的WET文件,并将文件的所有行读入一个列表中。
- 找到记录起始索引:
- 遍历文件行,找到包含"WARC/1.0"的行的索引,这些行标记了每条记录的开始。
- 初始化变量:
- 初始化一个空字符串
all_eng用于存储所有的英语内容,count_eng用于计数英语记录的数量。
- 初始化一个空字符串
- 解析英语内容:
- 遍历所有记录起始索引:
- 对于每条记录,检查第7行是否包含"WARC-Identified-Content-Language: eng",以确定该记录是否为英语内容。
- 如果是英语内容,从第10行开始,提取到下一个记录起始索引之前的所有行,并将其追加到
all_eng中。
- 遍历所有记录起始索引:
- 返回英语内容:
- 返回提取到的所有英语内容。
这两个函数分别用于打印评估结果到文件和从Common Crawl的WET文件中提取英语内容,为后续处理和分析提供了基础。
执行后终端输出如下

比如随意找一条

搜索引擎的结果如下

虽然这个信息没什么意义,但是也表明了这种攻击的提取能力。
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
网络安全学习资源分享:
给大家分享我自己学习的一份全套的网络安全学习资料,希望对想学习 网络安全的小伙伴们有帮助!
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
【点击免费领取】CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》
1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。【点击领取视频教程】

技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本【点击领取技术文档】

(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本【点击领取书籍】

4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。

最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…
👋全套《黑客&网络安全入门&进阶学习资源包》👇👇👇
这份完整版的学习资料已经上传CSDN,也可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


![Python自动化测试系列[v1.0.0][高效自动化设计]](https://img-blog.csdnimg.cn/20200415155030868.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)




![Pytest单元测试系列[v1.0.0][Pytest基础]](https://img-blog.csdnimg.cn/20200414100531977.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)




![暑假提升(3)[平衡二叉树之二--红黑树]](https://i-blog.csdnimg.cn/direct/f2964426c2cb4148ab29f5b79a4d5d4d.png)





